Оглавление:
- Марк Смалун
Социальные медиа: расширение выборки расширяет наши представления о потребителях. Как исследования в социальных медиа помогают другим видам исследований - Мартин Филц (Research Now), Стивен Джитлмен (Mktg, Inc.)
Оптимальное сочетание респондентов из исследовательских панелей и социальных сетей - Анни Петтит
Как обычное исследование - Хазеева Наталья
Социальные медиа: Vox Populi или специфика нового канала изучения мнения потребителей
Марк Смалун
Социальные медиа: расширение выборки расширяет наши представления о потребителях. Как исследования в социальных медиа помогают другим видам исследований
Перевод статьи выполнен Шашкиным А.В., Online Market Intelligence (OMI).
Социальные медиа. Сегодня этот модный термин стал частью нашей повседневной жизни. Это уже не концепция, а реальность. Социальные медиа - это то, что мы делаем, где мы находимся, как мы передаем свои чувства, эмоции и намерения и как потребители, и как маркетологи. В 2010 году социальные медиа продолжали быстро развиваться и стали темой активных обсуждений среди маркетинговых исследователей. Но настоящие примеры важности и ценности исследований социальных медиа еще впереди. Сейчас, когда споры еще продолжаются, можно ли игнорировать значение социальных медиа для нашей сферы деятельности? И (что еще более важно) можем ли мы игнорировать ту роль, какую социальные медиа играют в формировании нашего понимания поступков и мотивации современных потребителей?
Данная статья призвана вынести обсуждение темы исследований в социальных медиа на новый уровень, показав возможность использования интегрированных результатов трех различных методик – опросов по онлайн-панелям, телефонных опросов и исследований в социальных медиа. Аналогично параллельному исследованию, при котором обычно сравниваются результаты двух исследовательских панелей или двух методов рекрутирования, мы проведем одно исследование, где в качестве данных будут использоваться результаты использования трех различных методов исследования, каждый из которых дополняет и приумножает остальные методы.
С учетом того, что каждый источник данных имеет свое смещение, мы рассмотрим, как различные источники данных и методологии могут влиять на результаты и как сильные стороны одного метода могут компенсировать слабые стороны другого.
Мы также рассмотрим различные вопросы качества данных, влияющие на каждый метод. Поскольку эти методы существенно разнятся, мы не можем ожидать, что результаты будут одинаковыми. Отличающиеся методы рекрутирования и модальный коэффициент участия в данном исследовании приводят к тому, что в рамках каждого метода будут принимать участие разные типы респондентов и по разным причинам. Мы рассмотрим и оценим последствия этих сходств и различий.
Конечная цель состоит в том, чтобы показать, как сильные стороны одного метода основываются на слабых сторонах другого. Мы покажем, как с результатов использования одного метода начинается использование другого.
Исследование помогает исследованию: суть вопроса
Чем могу помочь? Это довольно распространенная фраза среди друзей, клиентов и коллег, но ее не часто услышишь в приложении к исследовательским методологиям. На просторах Интернета не утихает спор о том, какая методология лучше - фокус-группы, социальные медиа или опросы. Причина споров заключается в том, что нам самим больше всего нравится тот метод, которому нас (как исследователей) обучили и который мы регулярно используем. Но мы должны помнить, что наш любимый метод не является единственной методологией, способной решать проблемы. Наш любимый метод – это просто один из многих взаимодополняющих вариантов в постоянно расширяющемся наборе исследовательских инструментов. Давайте рассмотрим, как использование уникальных преимуществ каждого метода повышает общий успех проекта и в полной мере реализует возможности, заложенные в социальных медиа.
Исследования в социальных медиа помогают опросам №1
Давайте рассмотрим несколько приукрашенную цель исследования. Мы хотели бы узнать все, что связано с покупкой и потреблением кофе. Мы хотим знать: кто покупает, что покупают, где покупают, когда покупают и почему покупают кофе. Этакий большой, но необычный кофейный заказ.
Для большинства людей отправной точкой для данного исследовательского проекта стали бы опросы, учитывая тот факт, что им нет равных в получении репрезентативных данных со статистически определенной погрешностью (если вы волшебник, способный создать вероятностную выборку). Плюс ко всему, опросы отлично подходят для количественных и частотных измерений в рамках очень конкретных вопросов. Однако для решения всех наших исследовательских задач потребуется огромное число вопросов, что сделает опрос чрезмерно длинным. Для простого вопроса типа «Где вы покупаете кофе?» придется составить колоссальную таблицу возможных вариантов ответа, учитывающую сотни или даже тысячи торговых точек – кафе, баров и закусочных. Респондент не должен уставать во время опроса, а само исследование должно стать для него положительным опытом. Соответственно, исследователь должен использовать короткие вопросы и включать только наиболее актуальные варианты, но добиться этого не всегда легко.
Исследования в социальных медиа, не вызывая лишней усталости респондента, могут быть использованы для того, чтобы уменьшить количество вариантов ответа путем выявления тех вариантов, которые наиболее актуальны для потребителей. Для этого проекта мы собрали случайную выборку из 100 тысяч пользовательских обсуждений на тему кофе по всему Интернету - блогам, микроблогам, форумам и другим ресурсам. Затем мы подготовили облака слов для обеих интересующих нас категорий торговых точек: кафе и ресторанов быстрого питания.
Мы выяснили, что потребители, участвующие в социальных медиа, чаще упоминают Starbucks, Second Cup, Dunkin Donut и Coffee Time. То есть, как минимум, эти торговые точки должны быть включены в наши варианты ответа. Кроме того, мы также решили добавить McDonald's и Burger King, так как они упоминались среди наиболее популярных вариантов для второй категории. Эти данные помогли нам свести тысячи возможных вариантов всего до десяти, то есть до количества, приемлемого для наших респондентов
Исследования в социальных медиа помогают опросам №2
После запуска опроса и сбора данных мы получили репрезентативные оценки, которые можно разбить по любым сочетаниям переменных: возраст, пол, доход, размер семьи, регион и многое другое. Согласно нашим результатам, доля потребителей, купивших кофе в течение последних 30 дней в McDonald's, составила около 63% в США и около 52% в Канаде, что делает McDonald's самым популярным местом для покупки кофе «на ходу». Учитывая тот факт, что в техническом смысле McDonald's не является кафе и мы могли не включить его в первоначальный список возможных кафе, именно исследование в социальных медиа убедило нас в необходимости включить эту сеть фаст-фуд в список.
К сожалению, вторым по популярности местом для покупки кофе оказался ужасный раздел «Другое». Почему вариант «Другое» оказался столь популярным? Потому что за ним скрывается большое количество маленьких торговых точек? Или же потому что мы упустили из виду кого-то из крупных игроков рынка? И здесь на помощь снова приходят социальные медиа. Вместо создания облака слов по каждой из категорий общественного питания мы расширили количество вариантов, куда можно было добавить любую торговую точку и любое место, где покупается кофе. Облако слов выявило два интересных варианта, которые не были включены в изначальный список вариантов: АЗС и книжные магазины. Хотя ни один из этих вариантов не относится к торговым точкам общественного питания, наш опыт повседневной жизни подсказывает, что подобные варианты вполне правдоподобны. В самом деле, SMS-исследование, запущенное для оценки реального жизненного опыта потребителей, также дало много комментариев по АЗС. Соотнесение результатов мобильного исследования и исследования в социальных медиа заставило нас рассмотреть два варианта: 1) на АЗС и в книжных магазинах работает недостаточно кафе, не относящихся к сетевым брендам, 2) на АЗС и в книжных магазинах работают кафе, относящиеся к сетевым брендам, но их брендинг недостаточный сильный и заметный. В любом случае это означает, что тут требуются некоторые коррективы.
Как исследования в социальных медиа помогают SMS исследованиям
Одно из больших преимуществ SMS дневников заключается в том, что исследователи и бренд-менеджеры могут как бы прожить день из жизни потребителя, который пользуется их продукцией. Где они находятся в тот момент, когда пользуются этой продукцией? Что они делают в то время, когда пользуются ей? Кто находится рядом с ними? Что они видят? Участникам исследования не приходится напрягать память в попытках вспомнить нужный день, который был несколько недель или даже несколько месяцев тому назад. Им не приходится собирать воедино россыпь своих ощущений и впечатлений, потому что они в данную минуту непосредственно вовлечены в эту деятельность и одновременно участвуют в исследовании. В данном случае мы просили нескольких сотен участников исследования отправлять нам SMS-сообщение каждый раз, когда они покупали кофе, и рассказывать нам о состоявшейся покупке. За сутки мы получили сотни уникальных коротких текстовых сообщений.
Одна из проблем, связанная с подобными качественными данными (в частности, при работе с большими объемами данных), состоит в том, что для кодирования результатов требуется несколько человек. Каждый специалист по качественным исследованиям знает, что, когда на одном проекте работает несколько кодировщиков, всегда возникает вопрос согласованности их результатов, даже если они пользуются едиными принципами кодирования. Чем опытнее кодировщики, тем более точным получается кодирование, но и здесь результаты могут снижаться из-за усталости или потери внимания кодировщиков.
Здесь проявляется сильная сторона социальных медиа - их автоматизированные системы могут применяться к любому набору высказываний, будь то данные социальных медиа, суждения из открытых вопросов в количественных проектах или текстовые сообщения. Системы автоматизированного анализа контента могут определять темы, упоминаемые участниками исследования, и даже распознавать альтернативные формулировки и некорректное написание. Например, в этом исследовании текстовых сообщений многие люди указали, что они добавляли в кофе молоко. При этом некоторые респонденты писали, что «забелили» кофе или добавили «2%». Автоматизированная система кодировала каждую разновидность сленговых выражений или слов с грамматическими ошибками как «молоко», что обеспечивало согласованность всех данных.
Исследования в социальных медиа помогают опросам №3
Респонденты участвуют в опросах по разным причинам. Некоторые люди искренне заинтересованы в исследовательском процессе и хотят помочь производителям в улучшении и создании новых продуктов. Другие хотят участвовать в исследованиях ради вознаграждения. Существуют два основных вида вознаграждений, наиболее популярных среди участников опросов. Во-первых, они хотят получить некий финансовый стимул в виде денег или баллов. Второй вариант (сопоставимый по популярности с финансовым вознаграждением) – это информационные стимулы. Несмотря на то, что участники исследования помогают агентствам генерировать знания, сами агентства очень редко делятся с участниками такими знаниями (если вообще делятся). Респонденты просто хотят узнать результаты исследования, в котором они принимали участие, а также (возможно) те изменения, которые были сделаны по результатам их участия.
Тем не менее исследовательские агентства не готовы делиться такой информацией с респондентами, поскольку она является частной собственностью и из-за этого у них могут возникнуть проблемы. В качестве решения можно предложить такой вариант: в анкету добавляются еще несколько вопросов, ответы на которые можно будет предоставить респондентам. Однако в этом случае анкета становится слишком длинной, а этого мы стремимся избежать. К счастью, эта проблема не возникает в случае исследований в социальных медиа. Невообразимое количество данных на выходе позволяет легко подготовить информацию, которую можно будет безбоязненно предоставить респондентам. В рамках данного опроса мы подготовили набор результатов на основе исследования в социальных медиа специально для наших респондентов и переслали эти результаты участникам исследования в качестве благодарности. Легко, просто и всем приятно.
И это еще не все ...
Все вышесказанное - это лишь некоторые из тех способов, благодаря которым исследовательские методы могут оказывать друг другу поддержку. Но есть и другие. Например, многие исследования проводятся именно в тот момент времени, когда они требуются. А поскольку исследования в социальных медиа могут получать доступ к данным различных временных периодов, которые были зафиксированы месяцы и даже годы тому назад, результаты специальных исследований можно дополнять историческими данными и данными, собранными постфактум
Кроме того, результаты опроса или мобильного исследования можно углубить и детализировать с помощью исследования в социальных медиа. Например, в тех случаях, когда респонденты указывают, что вместе с кофе они любят есть сладости, исследование в социальных медиа может определить, какие именно сладости имеются в виду (пончики, печенье, кексы), а также выявить наиболее предпочитаемую вкусовую разновидность.
Или же в тех случаях, когда опрос не позволяет получить ответы на все «необходимые» вопросы в рамках 20-минутной анкеты, исследование в социальных медиа помогает получить ответы на такие вопросы и другую важную информацию о потребителях, которую просто нельзя узнать за 20 минут. Например, с какими знаменитостями ассоциируют себя ваши потребители, какие бренды одежды и обуви они предпочитают, какие автомобили и аудиосистемы им нравятся больше всего. Другими словами, те знания, которые необходимо собрать, чтобы создать маркетинговую кампанию с высокой степенью релевантности для ваших потребителей.
Заключение
Очевидно, что не существует какого-то единого исследовательского метода, который отвечал бы целям и задачам всех исследовательских проектов. У каждого метода есть свои явные преимущества и недостатки. Наша роль (как исследователей) состоит в том, чтобы понять нюансы каждого метода и максимально эффективно использовать их сильные стороны там, где это возможно. Там, где требуется высокая репрезентативность аудитории, мы должны использовать опросы. Там, где требуются данные в реальном времени, мы должны использовать мобильные телефоны. А там, где требуются большие объемы переменных, нам могут помочь исследования в социальных медиа. Мы должны помнить об этом. В свою очередь социальные медиа могут быть очень полезным каналом не только для проведения опросов, но и для того, чтобы услышать и получить информацию из обсуждений между потребителями. Исследовательский метод всегда определяется задачами исследования.
Мартин Филц (Research Now)
Стивен Джитлмен (Mktg, Inc.)
Оптимальное сочетание респондентов из исследовательских панелей и социальных сетей
Перевод статьи выполнен Шашкиным А.В., Online Market Intelligence (OMI).
Возможности
Статистика роста социальных сетей поражает. То, что когда-то было прерогативой молодежи, теперь приобрело широкий демографический охват (см. рис. 1). Facebook снес возрастные барьеры и проник практически во все демографические группы.

Источник: исследования Pew Research Center's Internet & American Life Project,
Сентябрь 2005 - май 2010 года. Все опрошенные в возрасте 18 лет и старше
Рисунок 1. Рост социальных сетей в разбивке по возрастным категориям
Только на Facebook имеется полтора миллиарда респондентов с уже готовыми профилями. Для сравнения: количество респондентов в исследовательских панелях, составляющих основу Интернет-исследований, насчитывает семь миллионов (ARF 2009). Этот дисбаланс свидетельствует о критической нехватке респондентов в наших онлайн-панелях. Таким образом, новые возможности сами идут нам в руки, и у нас должны быть проверенные методы для использования этих возможностей.
Онлайн-панели стремятся избегать чрезмерного использования своих баз респондентов. Включение респондентов из социальных сетей должно уменьшить это давление. Кроме того, оно позволяет исследовательской отрасли вовлекать в исследования людей, которые могут и не участвовать в онлайн-панелях. Результатом этого является более полная выборка, охватывающая большее количество групп.
В данной статье мы стремимся определить ту степень, в которой представителей социальных сетей, привлеченных с помощью компании Peanut Labs, можно было бы сочетать с уже имеющейся американской панелью Valued Opinions Panel (VOP) компании Research Now при сохранении характеристик исходной выборки панели.
Семь раз отмерь, один отрежь
Есть старая поговорка «Семь раз отмерь, один раз отрежь». Звучит довольно просто, но эта аксиома лежит в основе всей сферы стандартов качества – от ISO до Six Sigma. В этой поговорке – ключ к обеспечению качества: для этого требуется хороший измерительный инструмент, точность, соответствие конкретным целям, система оценки и система ведения учета. Небрежное обращение с линейкой и преждевременное решение «отрезать» испортит все дело: доски окажутся слишком короткими, крыша может не выдержать скопившегося снега, сделанный письменный стол будет выглядеть неаккуратно, а его ящики будут перекашиваться при попытках их выдвинуть.
Когда мы смешиваем выборки, мы должны подняться до стандартов тонкого мастера. Очевидно, что решение проблемы объединения источников выборки зависит от наличия правильной системы оценки, точности измерений, подходящих инструментов, а также понимания конечной цели, ради которой мы планируем использовать свои выборки.
Стандарты: минимально измеримое различие
В количественных исследованиях при сравнении совокупностей мы используем понятие статистически значимых различий. Существует некое пороговое значение, при котором различие столь мало, что статистика уже не может выявить эту разницу, и мы исходим из того, что эти две совокупности одинаковы. Под термином «минимально измеримое различие» мы понимаем наименьшее различие между двумя совокупностями, которое мы может статистически дифференцировать.
В целом же, мы будем определять различие между двумя совокупностями путем установления значения α (альфа), связанного с точностью, или вероятностью того, что две выборки различаются. То есть, мы можем определить, что две совокупности различны со значением α ≤ 0,05. В ситуации, когда наше измерение менее точно, мы могли бы использовать менее надежное значение α ≤ 0,1. Нам часто приходится идти на такой компромисс, когда мы вынуждены работать с небольшими или изменяемыми выборками.
Минимально измеримое различие – это способ определения порогового уровня, при котором мы начинаем обнаруживать статистическую разницу на столь низком уровне значения α, что она представляет собой консервативную степень сходства. Все, что находится ниже этого минимума, будет считаться необнаруживаемым различием. Вышесказанное можно сформулировать следующим образом: «В той степени, в какой мы не в состоянии обнаружить различие, мы можем считать две совокупности одинаковыми в рамках той системы оценки, которую мы используем».
В данном случае мы решили задать значение α на уровне одного стандартного отклоненения для выборки размером 1500. Изучение выборок различных размеров в онлайн исследованиях, проведенное компанией Mktg, Inc., показало, что мы использовали выборки с объемом более 1500 менее чем в 5% проведенных нами исследований. Таким образом, этот стандарт является консервативным.
Система оценки
Современная жизнь полна всяческих измерений. Интуитивно мы понимаем системы оценки, используемые для замера температуры, влажности, давления, скорости автомобиля, уровня холестерина в крови, калорийности продуктов и т.п. Эти измерения порой бывают настолько точными, что статистическая значимость в точных науках часто начинается на уровне α ≤ 0,01 и даже ниже.
Мы оцениваем поведение людей, поведение онлайн-аудитории. Такое поведение весьма переменно, будь то покупательские привычки, предпочтения в отношении СМИ или социографика. Весьма непросто создать систему оценки, которая отражала бы совокупности людей и их поведение. Поговорите со специалистом высокого уровня по Six Sigma, и он даст вам твердые наставления о необходимости измерений и введения соответствующих стандартов. Для достижения и поддержания нужного уровня качества нам необходимо создать систему оценки (метрику), сколь трудной ни была бы эта задача.
Стандарты
Слово репрезентативный вгоняет страх в сердца многих представителей профессии исследования рынка. В самом деле, нас сильно смущает любой вопрос о том, что может представлять наша выборка. Коротко говоря, «мы не знаем этого точно».
В данном случае мы отвергаем демографию как единственный подходящий самодостаточный стандарт для выборки в маркетинговых онлайн-исследованиях. Когда мы пытаемся проводить калибровку поведения только на основе демографии, мы исходим из того, что правильное распределение по демографическим признакам гарантирует нам надежную выборку моделей поведения. Мы обнаружили, что даже тщательно выравненные по демографии выборки из различных онлайн-источников могут демонстрировать значительные и значимые поведенческие различия между совокупностями (Gittelman and Trimarchi, Esomar 2010).
Наши стандарты должны относиться к тем характеристикам, репрезентативность которых мы стремимся обеспечить. В основе смешивания онлайн-выборок лежит потребность в таких стандартах. Мы должны проводить смешивание, имея ориентиром соответствующую цель. В исследованиях рынка мы оцениваем поведение. Обычно наиболее релевантными предметами нашего интереса выступают особенности покупательского поведения и другие пристрастия нашей целевой аудитории. Таким образом, при создании нашей системы оценки мы используем сегментацию по покупательскому поведению, намерению покупки, предпочтениям СМИ и социографическому поведению. Система оценки, которой мы пользуемся в Mktg, Inc., является результатом тщательно выверенной сегментации на основе данных, собранных в тридцати пяти странах и протестированных в течение четырех лет на двухстах онлайн-панелях.
Мы стремимся определить степень, в которой респондентов из социальных сетей (привлеченных Peanut Labs) можно смешивать с респондентами американской панели Valued Opinions Panel (VOP) компании Research Now. Наш анализ охватывал 4 009 американских респондентов из панели VOP (14.09. 2010 – 01.11.2010) и 3 871 американского респондента, привлеченного Peanut Labs из социальных сетей (14.09.2010 – 19.12.2010) с выборками, выравненными по параметрам Пол х Возраст х Доход.
В качестве стандарта мы использовали распределение по типам поведения, полученное на основе сбалансированных выборок из панели VOP. Мы могли бы использовать и другие стандарты, но в данном случае мы стремились обеспечить последовательную согласованность выборки VOP при добавлении респондентов из Peanut Labs. Мы использовали итеративную модель, чтобы определить, сколько пользователей социальных сетей (из Peanut Labs) можно добавить к выборке, прежде чем мы обнаружим минимальное измеримое различие в этой комбинации. В данном случае наша цель заключалась в получении последовательно согласованной смеси для устранения изменений в данных исследования, которая (в противном случае) могла бы быть создана изменениями в основной выборке.
Понять различия
Респонденты, приглашенные из социальных сетей, отличаются от тех, кто был набран через онлайн-панель. Эти различия проявляются в самих причинах их присутствия в Интернете. Те, кто использует арену социальных сетей для общения с другими людьми, получения новостей или развлечений, вероятно, будут отличаться от тех, кто выходит в Интернет только для совершения там покупок, управления своими банковскими счетами или для поиска наиболее дешевых авиабилетов. Те, кто используют социальный потенциал Интернета систематически, отличаются от тех, кто рассматривает глобальную паутину лишь как средство сделать свою обычную жизнь проще и удобнее. Поскольку многие наши онлайн-панели рекрутируются на основе сочетания коммерческих сайтов (таких как сайты продажи авиабилетов), различных программ вознаграждения или просто групп по интересам, они с высокой долей вероятности будут отличаться от тех, кто ищет социальные контакты или последние вирусные ролики на YouTube.
Сначала нам необходимо понять различия и выработать методы для добавления этой новой волны респондентов в уже существующие панели при сохранении последовательной согласованности результатов. Исследователи, использующие данные этих панелей, должны быть уверены в том, что добавление любых новых источников (в том числе социальных сетей) не внесет нестабильность в выборку и не увеличит отклонение данных.
Несмотря на то, что мы стараемся нивелировать различия в группах наших респондентов с помощью демографических квот, очевидно, что люди из социальных сетей значительно отличаются от остальных. При оценке уровня образования (см. рис. 2) у респондентов из социальных сетей с аналогичным распределением по параметрам Пол x Возраст x Доход, мы обнаружили, что уровень образования у этой совокупности гораздо ниже, чем у респондентов типичной онлайн-панели. Однако, несмотря на то что эти различия указывают на наличие проблем, демография еще не дает нам полной картины.
Респонденты, приглашенные из социальных сетей, отличаются от респондентов из панели, и степень такого различия определяет количество респондентов социальных сетей, которые могут быть добавлены к уже имеющейся выборке без ущерба для репрезентативности оригинальной панели в отношении поведенческих предпочтений. По мере углубления в различные демографические группы задача усложняется. Мы видим, что различия между группами не являются последовательно согласованными. Как правило, пожилые респонденты различаются сильнее, чем молодые.
1 - Структурные сегменты

|
Выпускники или аспиранты университета |
Выпускники колледжа |
|
|
Техникум или проф. училище |
Незаконченный колледж |
|
|
Среднее образование |
Незаконченное среднее образование |
Рисунок 2. Распределение респондентов в выборках по уровню образования
Идентификация структурных сегментов
Потребители в значительной степени различаются по своим мотивам и привычкам. Их выбор и покупка того или иного продукта или услуги определяется индивидуальными факторами. Поскольку демография сама по себе не способна обеспечить репрезентативность каждого из этих «сегментов» потребителей, важно выработать типологию, через которую их можно было бы идентифицировать для обеспечения поведенчески последовательной выборки. Процесс идентификации структурных сегментов можно представить в виде четырех этапов – от выбора переменных к выявлению сегментов и к разработке регрессионной модели.
Выбор переменных > Кластерный анализ > Регрессионная модель Logit > Результаты тестов
Эта задача выполняется на основе большого объема данных, собранного в одной стране, с целью обеспечения достаточно стабильной структуры. Оценки параметров из полученной регрессионной модели затем используются для назначения сегментов в других наборах данных, что создает внутренне согласованный набор различных групп респондентов. Требования к приемлемой схеме структурной сегментации представляют собой сложную задачу, поскольку полученная схема должна состоять из индивидуальных групп, различия между которыми сохраняются в различных выборках. Итоговая модель должна четко показывать принципы отнесения респондентов к сегментам, что может потребовать несколько итераций этого процесса для получения идеальной группы переменных.
Респонденты заполняли 17-минутную стандартную анкету с вопросами о медиапредпочтениях, использовании современных технологий, образе жизни и покупательских намерениях. Эти вопросы использовались для создания стандартного набора из трех структурных частей: (1) Покупательское поведение – часть, описывающая обобщенные покупательские привычки и включающая в себя 37 вопросов; (2) Социография, описывающая образ жизни и включающая в себя 31 вопрос, а также (3) Медиапотребление – часть, описывающая привычки использования СМИ и включающая в себя 31 вопрос. Каждый респондент был отнесен к одному из сегментов в каждой из трех схем сегментации, при этом каждая схема состояла из трех или четырех сегментов. Например, средний молодой мужчина мог быть классифицирован как «покупатель» в сегментации по покупательскому поведению, как «пользователь социальных сетей» в сегментации по социографии и как обычный «пользователь Интернета» в сегментации по медиапотреблению. Состав каждого сегмента представлен в следующих разделах.
1.1 – Сегментация по покупательскому поведению
Сегменты Покупательского поведения отражают основные различия в покупательском поведении респондентов. На рисунке 3 показан стандартизированный профиль сегментов на основе вопросов, включенных в анкету. Они касаются частоты пользования, частоты покупок, а также особенностей восприятия. Эти профили показывают степень влияния переменных при определении поведенческой классификации респондентов. Отклонения от нуля показывают положительное или отрицательное направление влияния на соответствующий сегмент.

Стандартные ошибки
Берут кредит / Не покупатели / Путешествуют (31%)
Покупатели (38%)
Чувствительны к цене / Не путешествуют / Не берут кредит (31%)
Рисунок 3. Стандартизированный профиль сегментации по покупательскому поведению
На рисунке 4 показано распределение этих сегментов между изначальной панелью VOP и альтернативным источником Peanut Labs. Стоит отметить, что в целом они значительно отличаются. Конечно, различия могут также варьироваться по подгруппам респондентов в этих источниках.

Берут кредит /Не путешествуют
Покупатели
Чувствительные к цене
Рисунок 4. Распределение в сегменте Покупательское поведение
1.2 - Социографическая сегментация
Социографические сегменты отражают различия совокупностей в отношениях, поведении и в некоторой степени образе жизни. На рисунке 5 показана значимость различных вопросов, используемых для выработки данной схемы сегментации. Как и в предыдущем разделе, это стандартизированные профили.
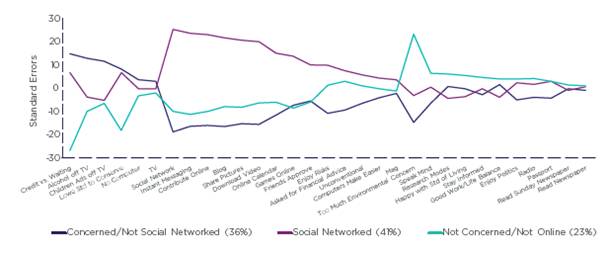
Заинтересованные / Не пользователи социальных сетей (36%)
Пользователи социальных сетей (41%)
Не заинтересованные / Не пользователи Интернета (23%)
Рисунок 5. Стандартизированный профиль для Социографических сегментов
На рисунке 6 показано распределение по социографическим сегментам между базовым и альтернативным источниками выборки. Здесь снова отмечаются большие различия.

Не заинтересованные / Не пользователи Интернета
Заинтересованные / Не пользователи социальных
Пользователи социальных сетей
Рисунок 6. Распределение по социографическим сегментам
1.3 - Сегментация по медиапотреблению
Сегменты медиапотребления отражают источники информации и использование респондентами различных медиа. Как и прежде, на рисунке (рис. 7) показана относительная значимость различных ответов на вопросы анкеты для формирования сегментов. Следует отметить, что сегмент, касающийся использования Интернета, вероятнее всего, будет зависеть от источников выборки респондентов.
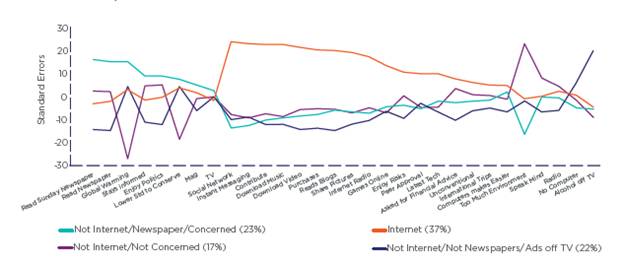
Не Интернет / Газеты / Заинтересованные (23%)
Не Интернет / Не заинтересованные (17%)
Интернет (37%)
Не Интернет / Не Газеты / Убрать рекламу с ТВ (22%)
Рисунок 7. Стандартизированные профили сегментации по медиапредпочтениям
На рисунке 8 показано распределение сегментов использования медиа между двумя источниками выборок. Как и следовало ожидать, имеются существенные различия.
Не Интернет / Не Газеты
Не Интернет / Не заинтересованные
Интернет
Не Интернет / Заинтересованные / Газеты
Рисунок 8. Распределение сегментов по медиапотреблению
2 - Максимальное соотношение смешивания
Поведенческие различия между выборками VOP и Peanut Labs являются значимыми. Соответственно, мы полагаем, что источники не являются непосредственно взаимозаменяемыми друг для друга. В тех случаях, когда последовательная согласованность данных является критически важной (волновые исследования, пред- / пост-исследования, трекинговые исследования), неконтролируемое введение респондентов из Peanut Labs в выборку панели Valued Opinions Panel может оказаться проблематичным. Такое смешивание может вызвать значительное изменение характеристик оригинального источника. Следовательно, практический вопрос о смешивании заключается не в поиске источников респондентов, которые будут в точности копировать респондентов панели. Вместо этого вопрос заключается в поиске правильного количества респондентов, которых можно добавить, не вызывая значительных изменений в результатах исследования.
И хотя такая модель смешивания может быть разработана для выборки в целом, отклонения между источниками, скорее всего, будут существовать внутри демографических групп. Таким образом, здесь требуется смешивание на основе демографических харакеристик. Соответственно, была использована демографическая матрица (по возрасту и полу). Вопрос для каждой ячейки в матрице звучал так: какая доля основной выборки может быть заменена альтернативной без внесения существенных изменений в ее характеристики.
2.1 – Параметры оценки
Есть две проблемы, связанные с измерениями. Первая - как измерить различия между двумя панелями. Вторая – какая разница является максимально допустимой. Поскольку мы имеем дело с простой (линейной) смесью, максимально приемлемое соотношение будет равняться максимально допустимой разнице, разделенной на измеренную разницу между смешиваемыми источниками данных. Полученная разница берется как «Среднеквадратическая разница». То есть квадратный корень среднего квадрата разности сегментов. Для Покупательского поведения, в которое входит три сегмента, она составит:

Distance - Мера различия
Segment(Host) – Сегмент (базовый)
Segment(Source) – Сегмент (допонительный)
Схема использования медиа состоит из четырех сегментов, что увеличивает количество элементов. Обратите внимание, что эти параметры оценки рассчитываются для каждой из схем сегментации.
Приемлемое различие соотносится с ожидаемой ошибкой измерения распределения сегментов. Она берется как Среднеквадратическая Стандартная Ошибка. Стандартная ошибка каждого сегмента определяется по формуле бинома:

Standard Error - Стандартная ошибка
Pi – это часть выборки в сегменте Segmentt изначальной совокупности, а N - это количество респондентов в таргетированной выборке. Отметим, что количество респондентов в ней не обязательно равно размеру выборки, используемой при измерении. Оно представляет размер исследований, для которых проводится этот тест. Общая стандартная ошибка – это корень из квадрата среднего этих стандартных ошибок:

Total Standard Error - Общая Стандартная ошибка
Наконец, приемлемый уровень берется как некая пропорция «β» общей стандартной ошибки. Мы можем рассматривать ее как «Ошибку 1-го типа», т.е. мы ищем минимально приемлемую вероятность того, что два образца одинаковы. Она обозначается как «α». В типичных статистических сравнениях, как правило, α задается на уровне 5%. Это означает, что две выборки одинаковы с вероятностью менее 5%. Это консервативный порог, выбранный учеными, чтобы свести к минимуму вероятность ошибочного представления о том, что конкретное внесение изменений окажет эффект. Тем не менее наша задача состоит в обратном. Мы хотели бы определить уровни, при которых наша изначальная и смешанная выборка не будут статистически различаться, и, таким образом, более высокое значение α является более консервативным и подходящим. В качестве допустимого предела мы установили порог на одной стандартной ошибке (которая равна примерно α = 32%) вместо обычных двух стандартных ошибок. Это дает нам два регулируемых параметра: целевой размер выборки и минимально допустимая вероятность.
Соответственно, приемлемый уровень равен:
Приемлемый уровень = β общего стандартного отклонения
А минимальное соотношение смешивания:
Минимальное соотношение смешивания = Приемлемый уровень / Мера различия
Как упоминалось ранее, расчет выполняется для каждой из трех схем сегментации. Общее максимальное соотношение смешивания берется как самое низкое из полученных значений. Это выполняется для каждой из демографических групп.
2.2 - Влияние целевого размера выборки и приемлемой вероятности
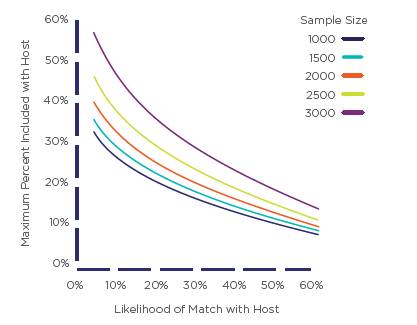
Общее максимальное соотношение смешивания вычисляется на основе взвешенной суммы отдельных демографических ячеек. На рисунке 9 показано распределение Общих максимальных соотношений смешивания в виде функции от α и N.
Размер выборки
Максимальный процент, включенный в базовую выборку
Вероятность совпадения с базовой выборкой
Рисунок 9. Общее максимальное соотношение смешивания как функция Приемлемой вероятности и Размера выборки на основе средних значений
Обратите внимание, что это соотношение уменьшается по мере увеличения α и N. По мере уменьшения допустимого отклонения (отражаемого этими факторами) при увеличении значений этих параметров количество респондентов, которые могут быть смешаны, уменьшается.
Мы выбрали целевой размер выборки в 1500 и α = 32%, или одну стандартную ошибку. Это соответствует тому, что мы считаем приемлемыми условиям для применения типичного смешанного источника. В случае с VOP и Peanut Labs среднее максимальное соотношение смешивания, равное 23%, позволяет охватить все демографические ячейки, хотя в действительности конкретный процент будет различаться между ячейками. Увеличение допустимого отклонения приведет к повышению максимального соотношения смешивания, и наоборот – уменьшение приведет к снижению, если требуются более консервативные оценки.
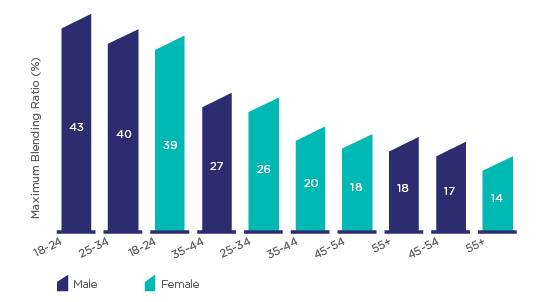
2.3 Отклонения в демографических ячейках
На рисунке 10 показано распределение максимальных соотношений смешивания для демографических ячеек с использованием усредненных значений. Оно варьируется от 14% для женщин старше 55 лет до 43% для мужчин в возрасте 18-24 года.
Максимальное соотношение смешивания (%)
Мужчины Женщины
Рисунок 10. Распределение максимального соотношения смешивания по демографическим ячейкам для средних значений
3 - Окончательная модель смешивания и максимальный эффект
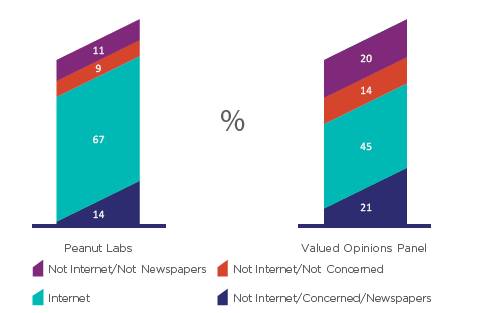
На рисунках 11-13 показано влияние процесса смешивания на основе трех основных сегментаций. Ожидается, что между панелью Valued Opinions Panel и смесью не должно быть никаких существенных различий, несмотря на то, что 18,8% смеси – это респонденты из Peanut Labs. На рисунке 14 показаны результаты для сегментов Покупательского поведения. И хотя между базовой выборкой и смесью существуют различия, в целом они являются незначительными.

|
Peanut Labs |
Valued Opinions Panel |
Смесь |
||
|
Чувствительные к цене |
Покупатели |
Берут кредит / Не путешествуют |
Рисунок 11. Распределение смеси по сегментам покупательского поведения
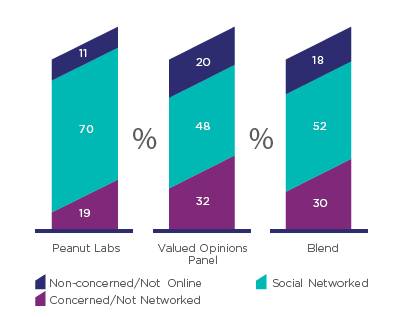
На рисунке 12 показаны аналогичные результаты для социографических сегментов. Очевидно, что (как отмечалось ранее) выборки Valued Opinions Panel и Peanut Labs очень разные. Но смесь очень близка к оригинальной панели. Выборки Смеси и Peanut Labs значительно отличаются при р <0,01.
|
Peanut Labs |
Valued Opinions Panel |
Смесь |
||
|
Не заинтересованные / Нет Интернета |
Пользователи социальных сетей |
|||
|
Заинтересованные / Не пользователи социальных сетей |
||||
Рисунок 12. Распределение смеси по социографическим сегментам
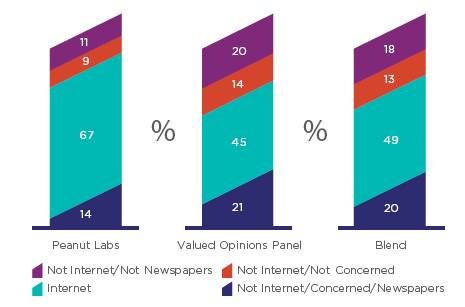
На рисунке 13 показаны результаты для сегментации по медиапотреблению - с теми же выводами. Разница между смесью и базовой выборкой незначительна по сравнению с той, что отмечена между смесью и Peanut Labs. Именно это сходство характеристик позволяет использовать смешанную выборку в качестве продолжения оригинальной панели без серьезных опасений по поводу последовательной согласованности. Выборки Смеси и Peanut Labs продолжают существенно отличаться.
|
Peanut Labs |
Valued Opinions Panel |
Смесь |
|
|
Не Интернет / Не газеты |
Не Интернет / Не заинтересованы |
||
|
Интернет |
Не Интернет / Заинтересованы / Газеты |
||
Рисунок 13. Распределение смеси по сегментам медиапотребления
4 - Влияние смешивания на поведение в ходе исследования
Процедура смешивания была разработана для того, чтобы гарантировать, что структурные сегменты смешанной выборки будут оставаться статистически похожими на изначальную панель при правильном контроле демографических групп. Однако введение смешанной выборки может изменить характеристики выборки с точки зрения проведения исследования, таких как сроки участия в панели, гиперактивность при участии в опросах и показатели качества ответов. Ожидаемые изменения подробно отображены на рисунках 17-19.
На рисунке 14 показаны данные о качестве участия в опросах, т.е. способности респондентов проходить вопросы-ловушки, с помощью которых проверяется вовлеченность респондентов в ход опроса. Всего было использовано три вопроса-ловушки. Первый – инструкция, где респондентам было предложено ввести определенное значение. Те, кто ввел неправильное значение, получали отметку «несоблюдение инструкций». Два других пункта содержали логически идентичные, но сформулированные противоположным образом вопросы, касающиеся уровня жизни и предпочтения между брендом и ценой. Внимательный респондент должен был дать противоположные ответы на эти вопросы. Те, кто не смог ответить правильно, помечались как «давшие противоречивые ответы». Как видно из статистики среднеквадратической ошибки, смешанная выборка существенно не отличается от выборки VOP по качеству ответов, но значительно отличается от дополнительной выборки во всех случаях за исключением вопроса про «уровень жизни».

|
Valued Opinions |
Смесь |
Peanut Lab Reference |
||
|
Несоблюдение инструкций |
Противоречивые ответы на вопрос об уровне жизни |
|||
|
Противоречивые ответы на вопрос о предпочтении бренда и цены |
||||
Рисунок 14. Качество ответов в различных выборках
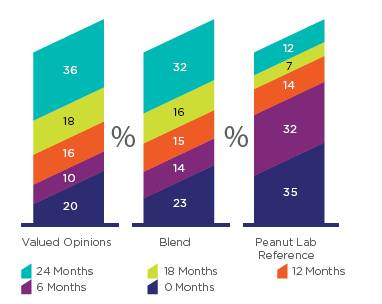
Существуют доказательства того, что изменения в длительности участия респондентов в панели могут привести к изменениям в данных. На рисунке 15 показано сравнение между распределением по длительности участия в панели в выборках Смесь, VOP и Peanut Labs.
|
Valued Opinions |
Смесь |
Peanut Lab |
||
|
24 месяца |
18 месяцев |
12 месяцев |
||
|
6 месяцев |
0 месяцев |
Рисунок 15. Распределение по длительности участия в панели
Рассмотренные выше характеристики качества ответов в исследовании рассчитываются на основе ошибок, допущенных респондентами, и длительности их участия в панели. Существует и третья группа характеристик, которая (как считается) может влиять на качество результатов. Это доля «спидстеров» (от англ. speedsters – респонденты, заполняющие анкету слишком быстро), а также «стрэйтлайнеров» (от англ. straitliners) - тех, кто дает похожие или одинаковые ответы на все вопросы в рамках исследования. На рисунке 16 показано распределение таких респондентов в различных источниках выборки. На основе среднеквадратической ошибки можно сказать, что количество спидстеров и стрэйтлайнеров в смешанной выборке существенно не отличается от выборки VOP или Peanut Labs.

|
Valued Opinions |
Смесь |
Peanut Lab |
||
|
Стрэйтлайнеры (~6% стандарт) |
Спидстеры |
|||
Рисунок 16. Распределение недобросовестных респондентов
Заключение
В данной работе мы вводим понятие минимально измеримого различия. Оно служит для обозначения того порогового минимального изменения в оценках, на основании которого мы делаем вывод о том, что между выборками существует различие. При любом менее существенном изменении совокупности считаются одинаковыми. Это контрастирует со стандартной статистической процедурой, в которой мы просто определяем наличие значимого различия между двумя совокупностями, без оценки того уровня, при котором разница была достигнута.
Пользователи социальных медиа представляют собой потенциальных респондентов для привлечения в исследования рынка. При этом они отличаются от респондентов, которых обычно можно найти в онлайн-панелях. В силу того, что оба источника выборки представляют собой разные и достаточно многочисленные группы, необходимо найти способ включить их в онлайн-исследования. Однако разница между двумя источниками выборки является и ресурсом, и потенциальной проблемой. Существующие панели в течение многих лет давали значимые данные, и резкое включение в них новых респондентов может привести к утрате последовательного соответствия в данных, чего следует избегать со всей осторожностью. Мы предложили консервативный и измеримый способ включения этих новых источников в точно дозированной форме. Наличие различий между демографическими ячейками определяет максимальный процент, который (на наш взгляд) может быть без ущерба добавлен к базовой совокупности респондентов онлайн-панели.
В настоящее время при добавлении этих респондентов в существующие панели лучше использовать консервативный способ оценки ошибок. Таким образом, мы использовали наиболее пессимистические сценарии в отношении объема выборки, доходов и размера статистически измеряемой разницы, допустимых при введении в наши выборки.
Управление онлайн-выборками смещается от заполнения квот к обеспечению правильности выборки в целом. Такой подход является чувствительным к адекватности восприятия – т.е. те, кто использует эти выборки, должны быть уверены, что изменения, наблюдаемые в данных, существуют в реальности, а не являются искусственным следствием, вызванным корректировкой в составных элементах источника выборки. Поставщики выборки обязаны обеспечить прозрачность данных, касающихся формирования выборки. Только наличие полной ясности позволяет практикам маркетинговых исследований понять, как интерпретировать полученные данные. И только благодаря наличию ясности конечные пользователи смогут понять, в какой степени они могут доверять полученным результатам.
После внедрения методологии, призванной обеспечить качество, ее уже нельзя будет рассматривать как «одноразовую» методологию, теряющую со временем свое значение: она не является ни статической, ни универсальной для всех случаев. В идеальном случае она должна отражать меняющиеся социальные, политические и экономические условия. Как и в случае с другими показателями качества, мы не считаем соотношение смешивания статическим параметром, поэтому следует регулярно применять сравнительный анализ.
Анни Петтит
Как обычное исследование
Сбор данных: Первый этап процесса сбора данных в рамках любого исследования – поиск людей, мнения которых можно будет собрать. Один из самых популярных источников – онлайн-панели, при этом каждая из компаний, создающих такие панели, владеет собственным секретом привлечения самых разных по своим качествам панелистов из самых разных источников. Они могут использовать разнообразные техники, такие как интернет-реклама, баннеры, партнерство с другими сайтами и другие методы привлечения для того, чтобы охватить как можно большее количество разных типов людей. Благодаря этому возможность смещения или искажения выборки сводится к минимуму.
При проведении исследований в пространстве социальных медиа сбор данных рассматривается примерно так же. Усилия направлены на выявление мнений людей (например, в обновлениях статусов, твитах, сообщениях, комментариях, ответах), собранных из максимально широкого круга различных источников. При том, что большинство клиентов интересуют сведения, собранные в Twitter и Facebook, интернет-пространство, подходящее для сбора мнений из социальных медиа, значительно более обширно. Внимание также должно уделяться мнениям, найденным в блогах (напр., Blogger, Wordpress), на видеохостингах (например, YouTube, MetaCafe), новостных сайтах (например, CNN, Fox News) и на многих других интернет-сайтах, где пользователи могут делиться своими мнениями в режиме онлайн. Получив доступ к максимально возможному количеству разнообразных сайтов, специалисты по сбору сведений смогут обеспечить минимальный уровень смещения или искажения выборки.
Качество данных: Мы проработали целые десятилетия в мире опросов и фокус-групп, выискивая множество проблем, связанных с обеспечением качества данных и борясь с ними. Мы выявили нерадивых респондентов, проставляющих одинаковые ответы в таблицах («стрэйтлайнеров»), и разработали методы отсеивания тех, кто, следуя этой тактике, отмечает явно некорректный ответ. Мы обнаружили респондентов, отвечающих на все вопросы слишком быстро, и разработали методы проверки качества ответов, чтобы исключать их из выборки. Мы создали методику отвлекающих маневров, тесты на проверку соответствия указанному возрасту и полу, тесты с самостоятельным вводом ответов на открытые вопросы и методы проверки соответствия респондентов необходимым критериям. Мы почти достигли той стадии, когда проводятся проверки для проверки проверок.
Повторюсь: процесс сбора данных в социальных медиа очень похож на процесс сбора данных для обычного исследования, и в нем наблюдаются те же проблемы, связанные с определением качества данных. Они могут немного отличаться по своей сути, но исследователи постоянно работают над их выявлением и создают методики точного определения качества данных для решения этих проблем. Например, общеизвестно, что определенные категории данных, таких как финансовые или фармацевтические данные, изобилуют спамом. Любой, кто ведет или читает немодерируемый блог или форум, знает все о таких комментариях в социальных сетях, как: «У вас самый лучший блог об обуви Adidas, покупайте «Виагру». Такие комментарии размещают на страницах блогов в надежде на то, что читатели, натыкаясь на них взглядом, в конечном итоге придут к мысли, что им нужно купить «Виагру». Конечно, подобные комментарии – хотя в них и упоминается заданный бренд – по сути, не имеют никакого отношения к самому бренду, и системы контроля социальных медиа стараются выявить и удалить их.
Существует и такая проблема качества предоставляемых сведений, как эмуляция общественной поддержки – особый вид рекламных кампаний, в рамках которых пользователям платят за написание положительных комментариев о каком-либо бренде на максимально возможном количестве различных интернет-сайтов. В данном случае организаторы подобной деятельности надеются на то, что люди, просматривающие эти сайты, подумают, что существует большая группа довольных потребителей, которым нравится тот или иной бренд. К счастью, комментарии такого типа также можно выявить с помощью тщательно настроенных автоматизированных систем. Несомненно, появятся и другие проблемы, связанные с обеспечением качества данных, однако мы продолжим отслеживать и устранять их и впредь.
Выборка: Отбор участников исследования – крайне важный процесс, который напрямую зависит от цели исследования. Независимо от того, что используется в качестве базы – существующая панель или списки клиентов какой-либо компании – у исследователей всегда есть определенная цель отбора, к которой они и стремятся. Возможно, необходимо сформировать демографически разнородную выборку или же выборку, состоящую из представителей предварительно отобранных целевых групп респондентов. В любом случае процесс проведения отбора позволяет нам удостовериться, что участники нашего исследования подходят для участия в данном проекте и обладают необходимыми для него знаниями, суждениями и мнениями.
Выявление людей, подходящих для какой-либо конкретной исследовательской цели может быть непростой задачей, но в случае с социальными медиа мы обладаем конкретными данными. Простое упоминание какого-либо бренда в социальной сети означает, что он имеет какое-то значение для данного человека. Он любит этот бренд, ненавидит его, покупает или, наоборот, избегает его, слышал о нем, ему порекомендовали его попробовать, он видел его по ТВ, или он хочет узнать, что это вообще такое. Существует некая причина, объясняющая упоминание этого бренда, и потому мнение данного человека становится важным. Социальные сети приносят определенную пользу в процессе сбора данных: исследователям не нужно пытаться выявить целевую аудиторию, аудитория социальных сетей сама идентифицирует себя для нужд сборщиков данных.
Взвешивание: Как бы ни старались исследователи, практически невозможно подобрать такой набор данных, который будет идеально соответствовать матрице выборки. Взвешивание позволяет нам добиться того, что даже в том случае, если мнения, полученные от участников выборки, не в полной мере отражают взгляды заданных категорий населения, то конечные результаты исследования все же будут соответствовать этому требованию. Например, если попытка сформировать выборку участников, отражающую по своей структуре данные переписи населения, привела к тому, что среди них оказалось 75% женщин и 25% мужчин, процедура взвешивания позволит нам интерпретировать полученные данные так, как если бы среди участников было 50% женщин и 50% мужчин.
Как и в случае обычного опроса, успех исследования в социальных медиа напрямую зависит от процедуры взвешивания, хотя используемые в них переменные различны. Вместо того чтобы проводить взвешивание на основе демографических характеристик участника, его проводят на основе источника получения необходимой информации. Взвешивание становится особенно важной процедурой в том случае, если вы приходите к выводу, что разные интернет-сайты привлекают разных пользователей и предоставляют совершенно разные объемы данных. Например, Twitter привлекает «ранних последователей», провоцирует пользователей на экспрессивные высказывания и генерирует множество данных. С другой стороны, Blogger привлекает тех, кто тщательно обдумывает свои идеи перед их публикацией в своем столь же тщательно продуманном блоге, и генерирует меньшие объемы данных.
Таким образом, даже если данные, полученные из Twitter, составляют 50% от общего объема сведений, исследователи могут счесть необходимым провести взвешивание этих данных, чтобы учесть тот факт, что только 13% от общего количества интернет-пользователей действительно используют Twitter. Неспособность определить, является ли взвешивание подходящим инструментом в каждом конкретном случае, может привести к тому, что полученные в итоге результаты нельзя будет распространить на всю целевую интернет-аудиторию.
Шкалирование: Превращение слов в цифры может показаться не относящейся к данному вопросу процедурой, однако на самом деле это ежедневное занятие каждого специалиста по маркетинговым исследованиям. При планировании исследования мы принимаем множество решений о том, как участники должны отвечать на наши вопросы. Мы решаем, какую шкалу будем использовать – трех-, пяти-, семи- или десятибалльную. Мы выбираем категории для этой шкалы, будь то степень привлекательности чего-либо, вероятность положительной рекомендации или покупки товара, степень удовлетворенности чем-либо или согласия с каким-либо утверждением. Когда все характеристики определены, мы просим участников исследования указать ту цифру на той или иной шкале, которая лучше всего отражает их мнение по данному вопросу. Например, респондент может выбрать вариант «скорее да» в вопросе о «вероятности приобретения товара марки А».
Те же методы применимы и в области социальных медиа. Исследователь выбирает наиболее подходящую для данного случая шкалу – трехбалльную (положительный ответ, нейтральный ответ, отрицательный ответ), пятибалльную (определенно да, скорее да, ни да, ни нет; скорее нет, определенно нет) или какую-либо другую. Так как для оценки отношения респондентов можно использовать числовую шкалу измерений, исследователь может сам определить, какая именно подойдет для его работы лучше всего.
Главное отличие в данном случае состоит в том, что уже не респондент решает, какое именно число лучше всего отражает его отношение, а сам исследователь выбирает наиболее подходящее число для каждого ответа. Например, исследователь может решить, что фраза «определенно куплю товар марки А» лучше всего соответствует коду «крайне положительное отношение к бренду». С другой стороны, он также может посчитать, что фраза «не покупаю такое барахло» относится к категории «скорее отрицательное отношение к бренду». Использование нецензурного слова при ответе может перевести фразу «не покупаю это *** барахло» в категорию «резко отрицательное отношение к бренду». Как и в случае обычного опроса, шкалирование – неотъемлемая часть процесса проведения исследования с помощью социальных медиа.
Переменные: Мы надеемся, что каждое исследование разрабатывается с учетом определенных целей. Независимо от того, какую именно работу необходимо провести для достижения поставленной цели – изучить опыт использования и отношение респондентов к определенному товару, провести сегментацию или периодический мониторинг рынка – цели данного исследования определяют то, какие именно вопросы нужно задать респондентам. Чтобы выполнить это требование, исследователи составляют вопросы о покупательском поведении, об особенностях рекомендации товаров, о том, как потребители пробуют новые товары и пользуются ими. Эти вопросы формулируются так, чтобы они соответствовали подготовленным нами шкалам оценок. Так, стандартный вопрос о покупках, может быть сформулирован таким образом: «Насколько велика вероятность того, что Вы приобретете товар марки А?».
Переменные величины также являются важным компонентом данных, полученных из социальных медиа. В данном случае переменные определяют сами респонденты, выбирая те темы, которые считают достаточно важными, чтобы поговорить о них. После того, как сведения о таких темах были получены, исследователи могут разработать соответствующие им переменные. Например, ответы на открытые вопросы, в которых фигурируют такие фразы, как «собираюсь купить», «хочу купить» и «собираюсь потратить на это некоторую сумму денег», будут отнесены к категории покупательских переменных. А ответы, в которых встречаются фразы типа «тебе стоит это купить» или «категорически рекомендую», попадут в категорию рекомендационных переменных. При соединении этих сведений с информацией об отношении респондентов к тому или иному предмету, переменные величины, полученные из социальных медиа, в сочетании с оценкой отношения респондентов будут напрямую соответствовать вопросам исследования.
Этические нормы: Этичность использования в исследовательских целях сведений, размещенных в социальных медиа, по-прежнему вызывает множество споров, однако существует целый ряд аспектов, на которые следует обратить внимание при составлении собственного мнения по данному вопросу. Как и в случае с обычными исследованиями, важнейшим принципом является проявление уважения к участнику исследования. Мы стараемся не злоупотреблять вниманием наших респондентов, хотя нам это и не всегда удается в тех случаях, когда мы просим их принять участие в 60-минутных опросах с множеством больших таблиц для заполнения. И мы стараемся не взаимодействовать, не мешать и не разговаривать с людьми при проведении наблюдательных исследований в торговых центрах и магазинах.
Подобным же образом при использовании данных из социальных медиа мы всегда должны с уважением относиться к тем, кто предоставляет нам сведения о себе. Мы должны помнить о том, что они не предоставляли нам эти сведения добровольно, не давали нам разрешения на дословное цитирование своих комментариев и не приглашали нас в свой канал в Twitter. Мы лишь сторонние наблюдатели и должны проявлять уважение при выполнении своей работы.
Выводы: Поначалу новые методики могут показаться слишком сложными. Однако если при их описании используются уже знакомые термины и методики, тогда то, что было новым и пугающим, становится знакомым и понятным. Сбор данных, обеспечение качества данных, отбор участников, взвешивание, шкалирование и определение переменных – все эти процедуры мы уже знаем и понимаем, и все они прекрасно работают в случае с данными, полученными из социальных медиа. Таким образом, исследование с помощью социальных медиа становится для нас старым добрым другом, таким же, как и обычные маркетинговые исследования.
Хазеева Наталья
Социальные медиа: Vox Populi или специфика нового канала изучения мнения потребителей
Социальные медиа (форумы, блоги, микроблоги и социальные сети) сравнительно недавно появились в России, но уже успели стать влиятельными, и формируют свою особую реальность со своей альтернативной повесткой дня. Активный рост интереса к социальным медиа в России начался в 2007 году, с ростом популярности социальных сетей, которые наиболее ярко демонстрируют все преимущества социальных медиа: возможность формирования контента самими пользователям, непосредственный обмен мнениями и информацией. О росте популярности социальных медиа наглядно свидетельствует число запросов по термину «социальные сети» в русскоязычной поисковой системе Google (рис. 1).

Рисунок 1. Динамика запросов по запросу «социальные сети» в русскоязычной по-исковой системе Google, 2004-2012 гг.
Изначально этот рост был связан с ростом количества зарубежных ресурсов: сначала блогоплатформы LiveJournal, а затем с ростом популярности микроблогов Twitter и соцсети Facebook (рис. 2).

Рисунок 2. Динамика запросов по популярным зарубежным социальным медиа в русскоязычной поисковой системе Google, 2004-2012 гг.
С 2007 года начинают преобладать русскоязычные социальные медиа, а именно соцсети «Одноклассники» и «ВКонтакте» (рис. 3), которые до сих пор удерживают уверенное лидерство по числу пользователей в России. Нужно отметить, что подобная ситуация – когда локальные соцсети опережают глобальные - наблюдается лишь в некоторых постсоветских странах (Белоруссии, Украине, Казахстане, Узбекистане, Латвии, Киргизстане, Молдове) и ряде исламских стран (например, Иран).

Рисунок 3. Динамика запросов по популярным российским социальным медиа в русскоязычной поисковой системе Google, 2004-2012 гг.
Все больше российских компаний рассматривают социальные медиа как новый и равноправный канал общения с потребителями, наряду с другими традиционными каналами коммуникации, такими как колл-центр, отделение банка или офис продаж и др. Соответственно вопрос, как реагировать на сообщения в социальных медиа, не стоит: работа с ними строится по тому же принципу, что и взаимодействие с потребителями через другие каналы обратной связи. И к такому выводу российские компании пришли на основе собственного опыта, когда недостаточное внимание к настроениям потребителей в социальных медиа оборачивалось значительным негативом и потерями репутации, а нередко и прямыми убытками. Значительное отличие данного канала коммуникации для компаний – большая резонансность (по сравнению с другими каналами коммуникации с клиентами). Негативный отзыв в социальных медиа (доверие к которому заведомо выше, чем к мнению журналиста или сотрудника компании) может молниеносно распространиться по сети и остаться там надолго.
Уже не подвергается сомнению тот факт, что социальные медиа влияют на нашу жизнь, а значит, и то, что их нужно изучать. Вопрос, пожалуй, заключается лишь в том, как изучать и, главное, интерпретировать эту реальность. Основываясь на опыте различных исследовательских проектов (изучения мнений в социальных медиа о брендах, компаниях и персонах, анализе аудитории блогов на протяжении двух лет), позволим себе сделать несколько выводов о специфике социальных медиа как канала выражения мнения потребителей (в широком смысле слова).
Первая и главная особенность обсуждения в социальных медиа – мнения потребителей в сети заведомо более поляризованы и критичны по сравнению с мнением всей целевой аудитории. Как правило, в блогах и на форумах не пишут нейтральные отзывы: нужен веский повод, чтобы потребитель потратил время и по собственной воле высказался о бренде Х или о персоне У. Во-вторых, тем, что бренды и компании отслеживают и реагируют на негативные суждения потребителей в сетях, они стимулируют появление именно негативных сообщений. Конечно, не следует делать вывод, что все потребители оставляют негативные отзывы только для того, чтобы решить свои проблемы во взаимодействии с брендом или компанией или «надавить» на них. Наши исследования показывают, что пока «массовый потребитель» не разглядел в социальных медиа орудия влияния на бренды и компании, но такие потребители, безусловно, существуют.
Поэтому в социальных медиа гораздо меньше нейтральных отзывов по сравнению с тем мнением, которое выявляется в ходе других исследований. Наш опыт показывает, что порядка 50% высказываний (чаще всего порядка 2/3-3/4 высказываний) оценочно нагружены, что очень высоко и не характерно для любого другого канала коммуникации или другого инструмента изучения мнения потребителей.
Значит ли это, что мнение аудитории социальных медиа необъективно по отношению к брендам и персонам и его не нужно принимать в расчет? Все зависит от того, с какой целью вы обращаетесь к этому мнению. Если вы хотите узнать уровень лояльности и доверия к вашему бренду, то, безусловно, для этого существуют другие релевантные инструменты измерения, например, массовые опросы. Но если ваша задача узнать, что потребителям нравится или не нравится в вашем продукте, сервисе, рекламной кампании, акции или даже товарной категории, то лучшего и более быстрого способа, чем изучение контента социальных медиа, не найти. Именно социальные медиа позволят, причем в кратчайшие сроки, выявить все болевые точки, нереализованные запросы потребителей и конкурентные преимущества. Здесь они будут видны как под увеличительным стеклом, и описанная выше смещенность мнения в социальных медиа оказывается очень полезной.
Чтобы показать ценность социальных медиа как источника данных в маркетинговых исследованиях, необходимо отметить еще несколько особенностей данного канала выражения мнения потребителей.
Это именно то, что реально думают потребители. Этих людей никто не просил высказываться, им никто не навязывал тему, они сделали это по собственной воле и без какой-либо оплаты или стимулирования со стороны модераторов. Безусловно, есть люди, которые «по заданию» хвалят или ругают бренды или компании, но, во-первых, их можно идентифицировать и вывести за скобки дискуссии, а во-вторых, они никогда не составляют большинства, а значит, не определяют настроения всей аудитории социальных медиа в целом или отдельного ресурса. Опытные исследователи всегда «вычислят» такие отзывы. Опять же, наши собственные исследования показывают, что и потребители могут выявлять такого рода отзывы не менее профессионально. Посетители сети обращают внимания на тон, адекватность отзыва, грамматику и рафинированность, стиль отзыва (наличие в нем рекламных формулировок, полных названий брендов и т.п.), а также надежность источника и самого автора (срок регистрации на ресурсе, наличие фото и других характеристик).
Почему потребители оставляют свое мнение в социальных медиа? Они хотят быть услышанными и изменить ситуацию. И с этих позиций они, безусловно, пристрастны. Однако это не противники, а добровольные помощники брендов и компаний, как бы странно это ни звучало, и именно так к этому следует относиться. Многие из этих добровольных помощников хотят не просто решить свою личную проблему, но и помочь другим потребителям, улучшить продукт или сервис компании, потребителями которой они являются. Ярким свидетельством тому является тот огромный отклик, который получают бренды в ответ на просьбу поделиться идеями. На своих страницах в соцсетях (так называемых «виртуальных представительствах брендов») или специальных сайтах, созданных для сбора идей потребителей (например, MyStarbacksIdea), бренды получают неимоверный отклик со скоростью в несколько тысяч идей в минуту.

Рисунок 4. Компания Disney в течение 20 минут получает свыше 3,5 тыс. ответов на свои вопросы в соцсети
На специализированных форумах и в сообществах собираются люди, которые целенаправленно и глубоко обсуждают различные темы – от автомобилей до средств автозагара. И такие потребители, безусловно, являются энтузиастами и увлеченными людьми, потребителями-экспертами. Кроме того, среди них немало креативных людей, которые самостоятельно пытаются улучшить продукт. Безусловно, такие потребители бесценны для брендов, и их потенциалом необходимо пользоваться, что и делают многие глобальные бренды-лидеры, вовлекая своих потребителей в процесс создания продуктов не в качестве пассивной стороны (когда бренды получают мнение потребителей, а затем анализируют его в одностороннем порядке), а в качестве полноправных участников процесса.
Потребители осознают силу мнения, высказанного в Интернете, и активно этим пользуются – не только в отношении компаний и продуктов потребительского сектора, но и органов власти. Есть примеры успешного использования возможностей сети для решения социальных вопросов и давления на власть, в частности, в Москве. Москвичам, например, удалось отстоять ряд образовательных учреждений от угрозы возможного закрытия, активно используя Интернет для распространения информации и отправки обращений в адрес региональных и федеральных властей с целью привлечения внимания к ситуации. И сила Интернета как влиятельного канала «обратной связи» и артикулирования интересов социальных групп была успешно опробована задолго до акций «сетевых хомячков» и протестных событий конца 2011– начала 2012 года.
Потребители высказывают свое мнение в Интернете более откровенно. Таких откровений не встретишь ни в одном другом исследовании; и такие яркие эмоции, сравнимые по накалу с политическими страстями, проявляются на, казалось бы, вполне нейтральные и неожиданные потребительские темы. Откровенность поощряется анонимностью высказываний. Как правило, не составляет труда понять отношение высказывающихся к персонам и брендам: зачастую используется ненормативная и неформатная лексика, смайлики и другие символы (которые призваны нивелировать недостатки опосредованного общения, компенсируя недостаток визуального контакта повышенной эмоциональностью высказываний), другие устоявшиеся приемы общения в Интернете (специфические выражения, слова прописными буквами и др.).
Безусловно, есть темы, на которые аудитория интернета не готова откровенно высказываться в открытом Интернете (прежде всего, связанные со здоровьем, личными финансами и др.), но на большинство потребительских тем отклик будет более откровенный, нежели мнения, полученные в рамках других типов исследований. Однако и вполне деликатные темы, такие как собственное здоровье, пользователи Интернета готовы обсуждать в социальных медиа достаточно откровенно (в кругу зарегистрированных пользователей). Пример тому – успешная англоязычная социальная сеть пациентов PatientsLikeMe.com, которая существует уже 7 лет и в которой 154 тыс. пациентов со сходными диагнозами обсуждают связанные со здоровьем вопросы.
Оценки без оценок. Несмотря на то, что мнение пользователей социальных медиа часто содержит вполне открытые и недвусмысленные оценки, прямые оценочные характеристики (по типу «плохой – хороший») там присутствуют крайне редко. Например, наше исследование в области банковских услуг показало, что только 3-8% сообщений содержат оценочные характеристики. По большому счету оценку можно давать двумя способами: (1) с помощью прямых оценок и (2) с помощью фактов и демонстрации отношения. В социальных медиа преобладают оценки второго типа. Никто не делает обобщений, что бренд или компания плохая или хорошая, там просто сообщают о собственном опыте: простоял в очереди, купил просроченный продукт, получил некомпетентный ответ, потерял полдня, нагрубили и т.п. Или потребитель весьма красноречиво демонстрирует свое отношение к бренду или компании: «достал», уйду в другую компанию, не буду покупать здесь и т.п. В равной мере это справедливо и в отношении выражения позитивных оценок.
Именно эта особенность мнения потребителей в социальных медиа - «оценочность без оценок» - наиболее ценна для компаний и брендов, так как позволяет наиболее точно понять основные проблемы и, если угодно, получить «аргументированное мнение потребителей». А тот факт, что это реальное «наболевшее» мнение, позволяет быть уверенными в том, что выявленные узкие места являются топпроблемами для значительной части потребителей. Опять же, если потребитель делится своим позитивным мнением, можно быть уверенным, что это реальное преимущество бренда, компании или персоны. Важно подчеркнуть, что в большинстве случаев это мнение реальных пользователей, которые действительно сталкивались с продуктом или услугой. И зачастую эти потребители лучше знают особенности продукта или услуги, чем служба поддержки компании. Доказательством тому является тот факт, что нередко потребители дают друг другу дельные советы и корректируют ответы представителей компаний.
Таким образом, мнения в социальных медиа более выпуклые, если угодно, гипертрофированные, яркие, эмоциональные и откровенные, что делает их хорошим объектом для изучения. Но это не единственное отличие социальных медиа как канала выражения мнения потребителей. Важно, что анализ социальных медиа позволяет выявить некоторые значимые характеристики и особенности настроений потребителей.
Первая и главная особенность социальных медиа – умение чутко улавливать и отражать настроения потребителей и содержать инсайты. Помимо того, что социальные медиа отражают крайнее полярное отношение к персонам и брендам, они способны демонстрировать и мейнстрим (общее доминирующее настроение), и улавливать новые тенденции и настроения потребителей. Анализ социальных медиа позволяет получить оперативный срез общественных настроений Интернет-аудитории. Именно это делает его полноценным каналом выражения мнений, а не кривым зеркалом.
Настроения потребителей выявляются, например, при анализе основных тем и основных информационных поводов для обсуждения. Так, потребители могут долго и бурно обсуждать совсем не те информационные поводы, которые поставили на повестку дня традиционные печатные и электронные СМИ. В условиях, когда у традиционных масс медиа нет больше монополии на информационное пространство, расхождения в повестке дня становятся все более заметны. Достаточно сравнить топновости в СМИ и топ-темы в блогах, чтобы увидеть, что такие расхождения случаются регулярно. Практически каждый день в топ-темы блогосферы попадают вопросы, не нашедшие широкого освещения в информагентствах, прессе, радио и телевидении.
Юмор – выразитель настроений потребителей. Юмор еще более показателен в качестве выразителя доминирующих настроений и отношения к персонам и брендам. Юмор весьма активно присутствует в социальных медиа. Примером могут служить высказывания на тему йогуртов в нашем исследовании, которые многое говорят о потребительском поведении:
«Окончание срока годности йогурта означает, что бифидобактерии перешли на сторону зла».
«Многие покупают в магазине зеленый чай и йогурт, потому что надо следить за своим здоровьем, и пельмени с майонезом, потому что «Ну надо же что-то пожрать...»
«Дорогая, я, конечно, хотел купить тебе бриллиантовое кольцо, но ювелирные были закрыты, поэтому я купил тебе йогурт».
«Почему блондинки открывают йогурт прямо в супермаркете? Потому что на крышечке написано: «открывать здесь».
«Если пустой стаканчик из-под йогурта в раковине, значит ложка должна быть в мусорке».
И он популярен не только потому, что живущие в Интернете народные шутки остроумны и ярки, но и потому, что бьют в самую точку: тонко и предельно точно отражают отношение аудитории к бренду, компании или явлению и выявляют основные «болевые точки». Такой народный фольклор присутствует исключительно в социальных медиа, и с помощью других методов измерения мнения аудитории практически не выявляется.
Анализ дискуссии в социальных медиа также позволяет выявить столь необходимые для всех инсайты. Так, к примеру, в ностальгических зарисовках «вы тоже делали это» выяснилось, что многие потребители облизывают крышку от йогурта. И, что более всего интересно, потребители приходили в восторг, прочитав такое откровение и с удивлением узнав в этом себя. Такую ситуацию, когда потребитель может сказать «да, это именно про меня!», «вы меня понимаете», в маркетинговых исследованиях и называют инсайтом. И такой инсайт выявляется естественным образом, его не «назначает» исследователь с помощью сложных методик анализа, а выбирает сам потребитель. А потому такие инсайты не требуют дополнительной верификации со стороны потребителей.
Анализ дискуссий в социальных медиа позволяет выявить нереализованные потребности аудитории. В социальных медиа уже собрались потребители, которые готовы высказать свое мнение о бренде или компании и рассказать, чего им не хватает. И опять же по этому параметру с социальными медиа не может сравниться ни один канал изучения мнения потребителей.
И, что немаловажно, в социальных медиа несложно выявить мнение, которое поддерживается не одним, а несколькими и даже многими пользователями. Это могут быть вопросы, вокруг которых неожиданно возникает обсуждение, или посты, которые вдруг оказываются созвучны и близки большому числу пользователей Интернета, и эти сообщения начинают репостить. Так, при анализе темы йогуртов неожиданно проявилась достаточно бурная дискуссия на тему того, какими приборами едят йогурт. Потребители сообщали об экзотических способах употребления йогурта в условиях отсутствия столовых приборов и делились советами, как съесть меньше. Такая дискуссия весьма показательна: она демонстрирует, что социальные медиа позволяют выявить нереализованные потребности и потенциальные новые ниши для производителей.
Мы обозначили лишь некоторые основные особенности социальных медиа как канала выражения мнений потребителей. Полноценного и весьма важного канала с точки зрения качества и многообразия получаемой информации, как мы постарались показать. Это позволяет считать анализ социальных медиа полноправным методом изучения мнения потребителей наряду с другими известными и широко применяемыми методами. Однако из этого не следует, что он превосходит или отменяет другие методы изучения мнений потребителей. Каждый метод исследования хорош и уместен для решения определенного круга задач. И анализ социальных медиа найдет свое место в ряду исследовательских методов.
Изучение социальных медиа социологами и специалистами в области маркетинговых исследований всецело вписывается в новую парадигму «listening is a new asking» ( новый способ задавать вопросы – это слушать), в рамках которой активно развиваются пассивные методы измерения и где за анализом социальных медиа закрепился термин «нетнография» (от слов «этнография» и «net», сеть). Действительно, зачем задавать вопросы, когда в современном интерактивном мире web 2.0 уже достаточно способов услышать потребителей?




